TRI Authors: Vitor Guizilini, Rares Ambrus, Sudeep Pillai, Jie Li and Adrien Gaidon
All Authors: Vitor Guizilini, Rares Ambrus, Sudeep Pillai, Jie Li and Adrien Gaidon
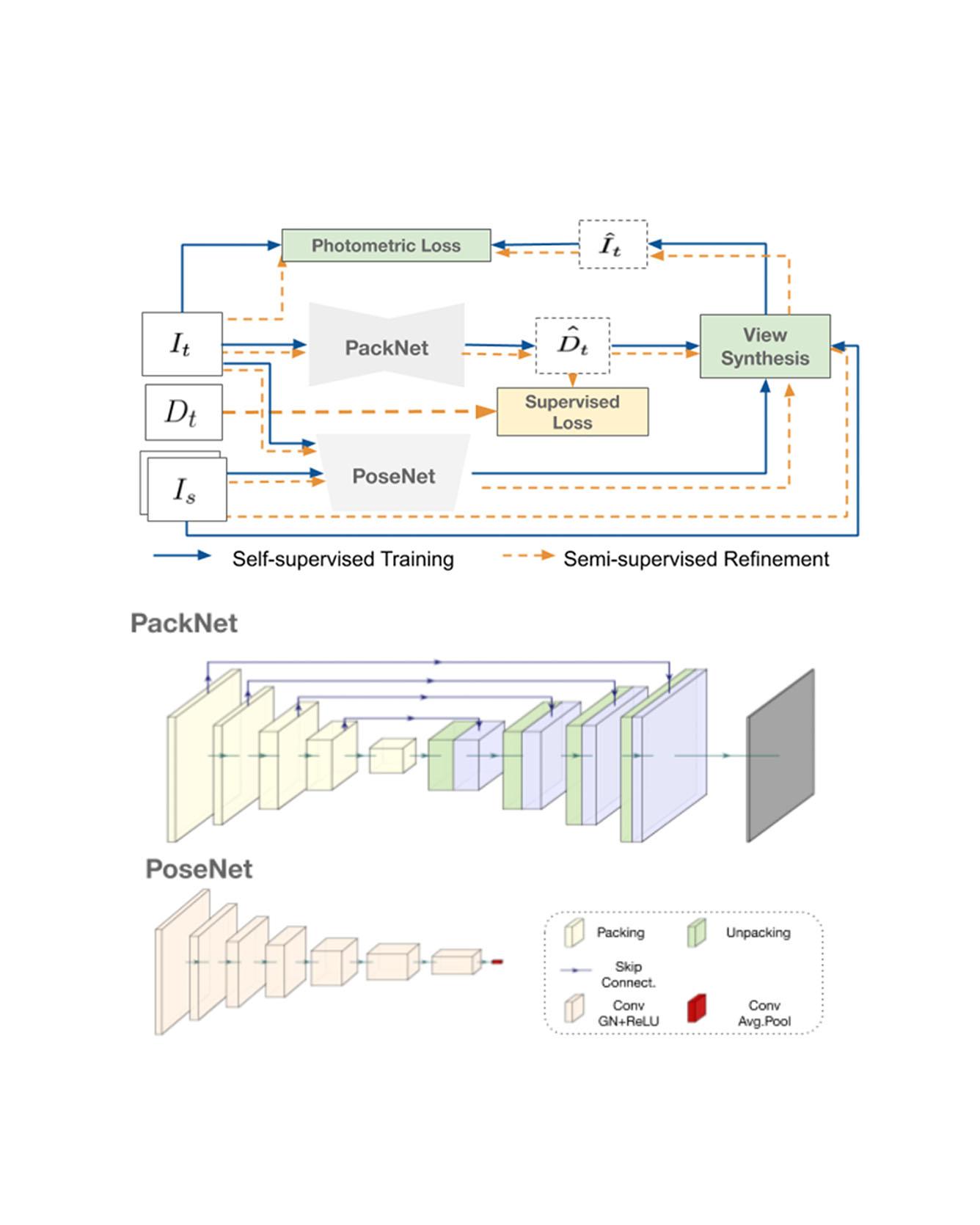
Dense depth estimation from a single image is a key problem in computer vision, with exciting applications in a multitude of robotic tasks. Initially viewed as a direct regression problem, requiring annotated labels as supervision at training time, in the past few years a substantial amount of work has been done in self-supervised depth training based on strong geometric cues, both from stereo cameras and more recently from monocular video sequences. In this paper we investigate how these two approaches (supervised & self-supervised) can be effectively combined, so that a depth model can learn to encode true scale from sparse supervision while achieving high fidelity local accuracy by leveraging geometric cues. To this end, we propose a novel supervised loss term that complements the widely used photometric loss, and show how it can be used to train robust semi-supervised monocular depth estimation models. Furthermore, we evaluate how much supervision is actually necessary to train accurate scale-aware monocular depth models, showing that with our proposed framework, very sparse LiDAR information, with as few as 4 beams (less than 100 valid depth values per image), is enough to achieve results competitive with the current state-of-the-art. Read More
Citation: Guizilini, Vitor, Jie Li, Rares Ambrus, Sudeep Pillai, and Adrien Gaidon. "Robust Semi-Supervised Monocular Depth Estimation with Reprojected Distances." In Conference on Robot Learning (CoRL) 2019.