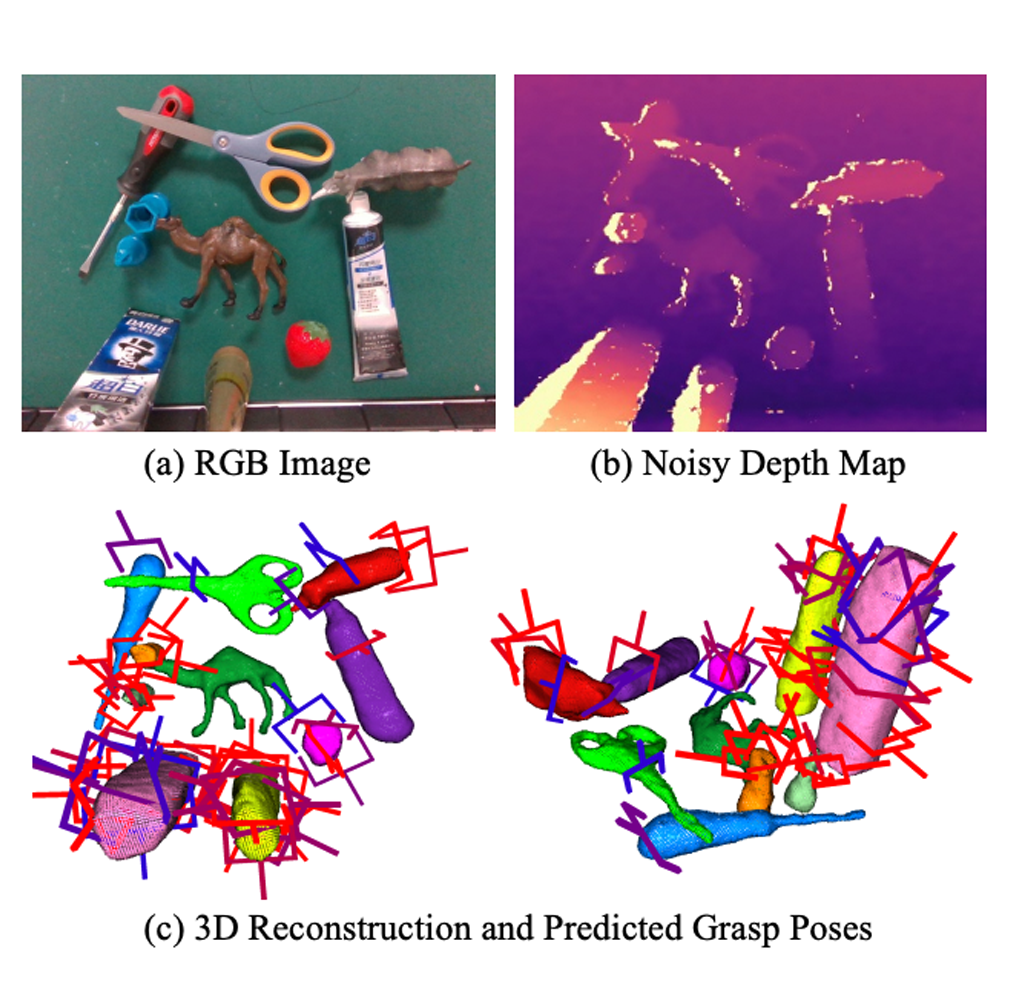
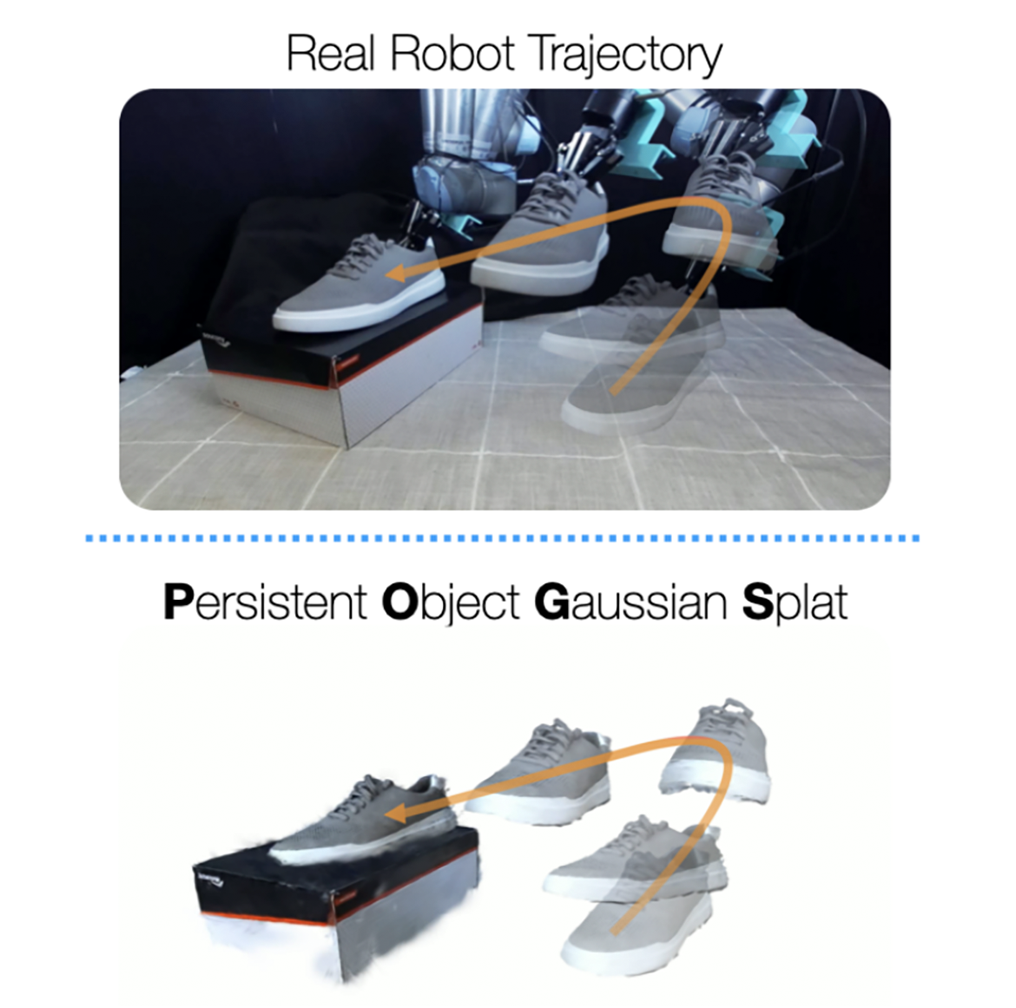
If robots are to work effectively alongside people, they must be able to interpret natural language references to objects in their 3D environment. Understanding 3D referring expressions is challenging—it requires the ability to both parse the 3D structure of the scene and correctly ground freeform language in the presence of distraction and clutter. We introduce Transcrib3D, an approach that brings together 3D detection methods and the emergent reasoning capabilities of large language models (LLMs). Transcrib3D uses text as the unifying medium, which allows us to sidestep the need to learn shared representations connecting multi-modal inputs, which would require massive amounts of annotated 3D data. As a demonstration of its effectiveness, Transcrib3D achieves state-of-the-art results on 3D reference resolution benchmarks, with a great leap in performance from previous multi-modality baselines. To improve upon zero-shot performance and facilitate local deployment on edge computers and robots, we propose self-correction for fine-tuning that trains smaller models, resulting in performance close to that of large models. We show that our method enables a real robot to perform pick-and-place tasks given queries that contain challenging referring expressions. Code will be available at https://ripl.github.io/Transcrib3D. READ MORE