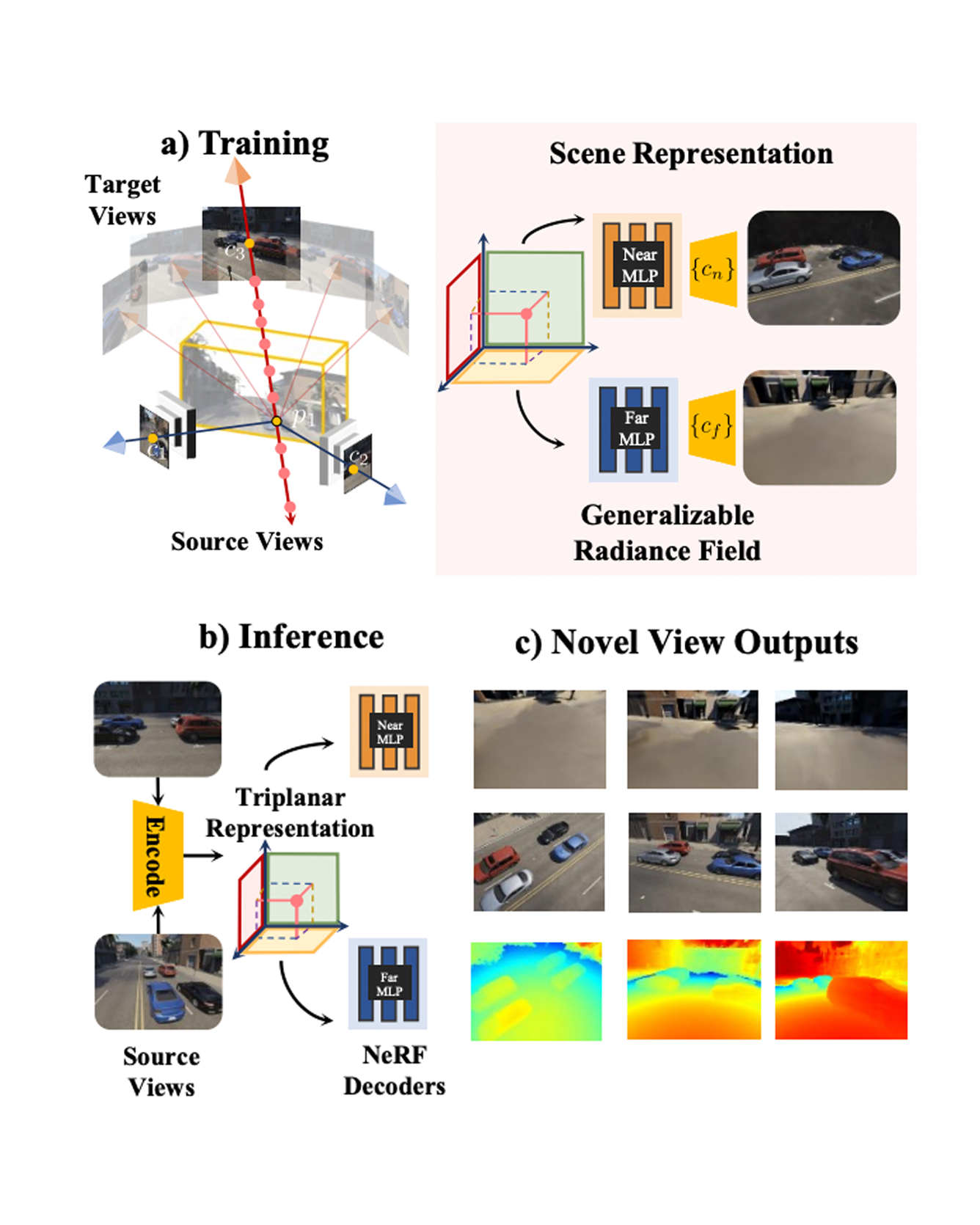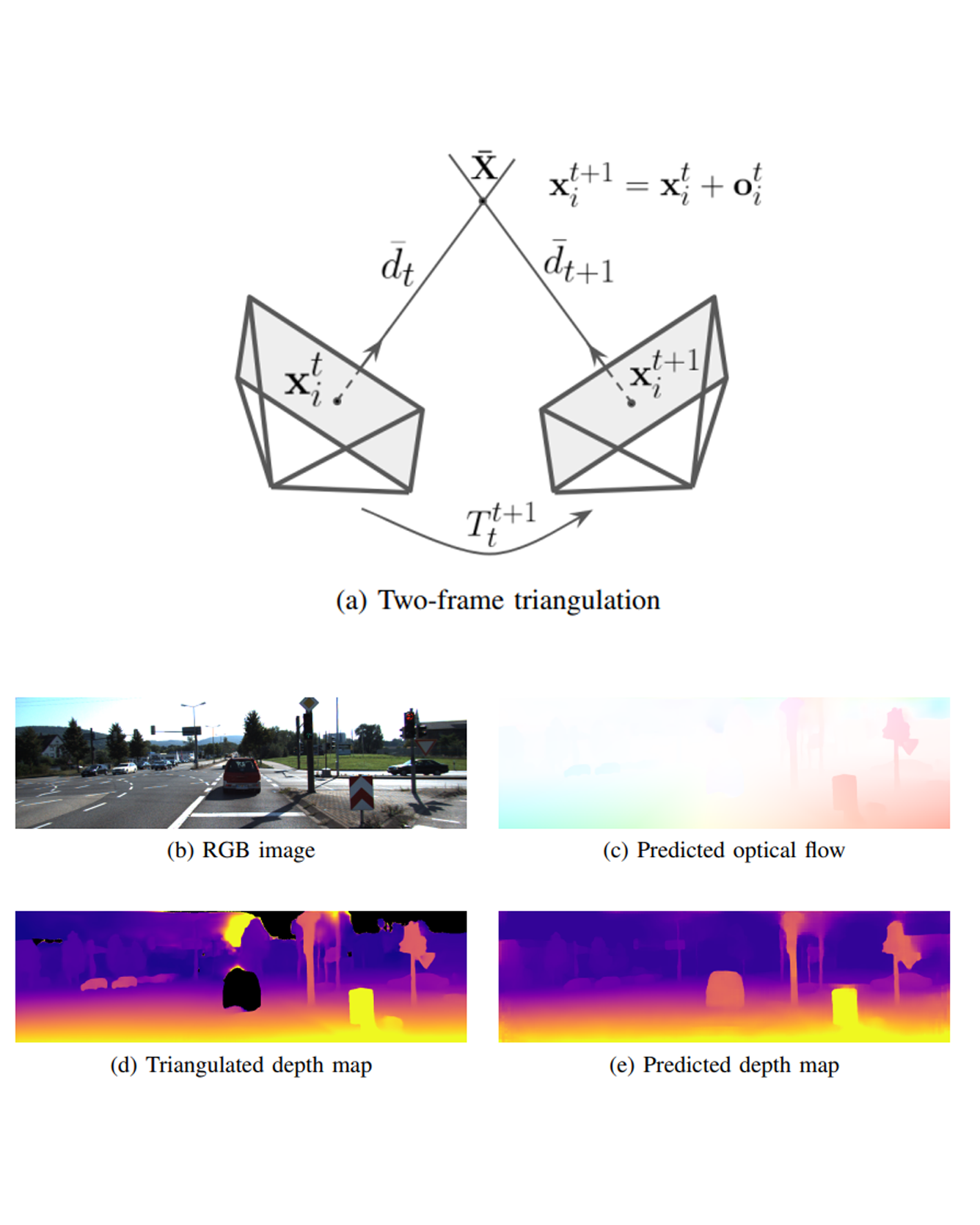
Self-supervised monocular depth estimation enables robots to learn 3D perception from raw video streams. This scalable approach leverages projective geometry and ego-motion to learn via view synthesis, assuming the world is mostly static. Dynamic scenes, which are common in autonomous driving and human-robot interaction, violate this assumption. Therefore, they require modeling dynamic objects explicitly, for instance via estimating pixel-wise 3D motion, i.e. scene flow. However, the simultaneous self-supervised learning of depth and scene flow is ill-posed, as there are infinitely many combinations that result in the same 3D point. In this paper we propose DRAFT, a new method capable of jointly learning depth, optical flow, and scene flow by combining synthetic data with geometric self-supervision. Building upon the RAFT architecture, we learn optical flow as an intermediate task to bootstrap depth and scene flow learning via triangulation. Our algorithm also leverages temporal and geometric consistency losses across tasks to improve multi-task learning. Our DRAFT architecture simultaneously establishes a new state of the art in all three tasks in the self-supervised monocular setting on the standard KITTI benchmark. READ MORE